加密存储及其检索技术在云存储中的应用
云计算自身的数据安全问题阻碍其推广应用,我们在分析云存储应用中的存储安全技术基础上,针对加密存储的需求,基于常见的加密检索方法和相关技术,我们提出了一种基于全同态加密的检索方法,该方法能在一种程度上提高检索效率。
一、云存储应用中的加密存储技术
大规模高性能存储系统安全需求,特别是云存储应用中,可扩展和高性能的存储安全技术,是推动网络环境下的存储应用(如云存储应用)最根本的保证,已经成为当前网络存储领域的研究热点。云存储应用中的存储安全包括认证服务、数据文件加密存储、安全管理、安全日志和审计。
访问控制服务实现用户身份认证、授权,防止非法访问和越权访问。主要功能包括:用户只能对经管理员或文件所有者授权的许可文件进行被许可的操作;管理员只能进行必要的管理操作,如用户管理、数据备份、热点对象迁移,而不能访问用户加密了的私有数据。
加密存储是对指定的目录和文件进行加密后保存,实现敏感数据存储和传送过程中的机密性保护。
安全管理主要功能是用户信息和权限的维护,如用户帐户注册和注销等,授权用户、紧急情况下对用户权限回收等。
安全日志和审计是记录用户和系统与安全相关的主要活动事件,为系统管理员监控系统和活动用户提供必要的审计信息。
对用户来说,在上述4类存储安全服务中,存储加密服务尤为重要。
加密存储是保证用户私有数据在共享存储平台的机密性核心技术。
随着存储系统和存储设备越来越网络化,存储系统在保证敏感数据机密性的同时,必须提供相应的加密数据共享技术。保护用户隐私性要求存储安全建立在对存储系统的信任基础之上。必须研究适用于网络存储系统的加密存储技术,提供端到端加密存储技术及密钥长期存储和共享机制,以确保用户数据的机密性和隐私性,提高密钥存储的安全性、分发的高效性及加密策略的灵活性。在海量的加密信息存储中,加密检索是实现信息共享的主要手段,是加密存储中必须解决的问题之一。
二、加密信息检索技术
对加密信息检索的研究始于2000年,主要包括以下几种方式:
1、线性搜索算法
在线性搜索算法中,首先用对称加密算法对明文信息文件加密。对于每个关键词对应的密文信息,生成一串长度小于密文信息长度的伪随机序列,并生成一由伪随机序列及密文信息确定的校验序列。伪随机序列的长度与检验序列长度之和等于密文信息的长度。伪随机序列及检验序列对密文信息再次加密。在搜索过程中,用户提交明文信息对应的密文信息序列。在服务器端,密文信息序列被线性地同每一段序列模2加。如果得到的结果满足校验关系,那么说明密文信息序列出现,否则,说明密文信息不存在。
线性搜索方法是一种一次一密的加密信息检索算法,因此有极强的抵抗统计分析的能力。但其有一个致命的缺点,即逐次匹配密文信息,这使得这种检索方法在大数据集的情况下难以应用。
2、基于关键词的公钥搜索
基于关键词的公钥加密搜索算法由其目的是可以在用户端存储、计算资源不足的情况下,通过访问远端数据库获取数据信息。存储、计算资源分布具有不对称性,即用户的计算存储能力不能实时满足其需求。另一方面用户在移动情况下存储、索引数据的需求也有增加,比如Email服务等。在这种特定情况下,需要保护用户的数据隐私。加密数据有多个不同来源,针对这一问题的解决方法是加密算法使用公钥加密。
算法的过程如下,首先生成公钥、私钥,然后对待存储的明文关键词用公钥进行加密,生成可搜索的密文信息。
3、安全索引
安全索引解决了简单索引方式易受统计攻击的问题。其机制是每次加密所用的密钥是事先生成的一组逆Hash序列,加密后的索引被放人布隆过滤器中。当检索的时候,首先用逆Hash序列密钥生成多个陷门,然后进行布隆检测。对返回的密文文档解密即可得到所需检索的文档。
针对有新用户加入、旧用户退出的多用户加密信息检索,这是一种解决方法。但其存在的缺陷是需要生成大量的密钥序列,随着检索次数的增加,每多进行一次检索,其计算复杂度均线性增加。这在实际应用中很难被接受。
在以上提到的多种加密信息检索算法中,所用的检索模型都是布尔模型,因而无法根据查询与待检索文档的相关度进行排序操作。在实际情况中,尤其是在数据规模较大的云存储应用中,包含某一查询关键词的文档可能有很多个,如何在多个可能相关的文档中找出最相关的一个或若干个文档是需要解决的问题。对加密的文档,是否可以应用成熟的向量空间模型,进而进行相关排序,是一个开放的问题。
4、引入相关排序的加密搜索算法
在这一算法中,每一文档中关键词的词频都被保序加密算法加密。加密文档被提交查询给服务器端后,首先计算检索出含有关键词密文的加密文档;然后对用保序算法加密的词频对应的密文信息进行排序处理;最后把评价值高的加密文档返回给用户,由用户对其进行解密。
这一种方法可以在给定多个可能相关文档的情况下对加密文档进行排序,进而把最可能相关的文档返回给用户。但这一种算法首先不适用于一个查询包含多个查询词的情
况,其次算法只利用了文档中的词频信息,无法利用词的逆文档频率,进而向量空间模型无法直接应用。解决前一种问题的一种方法是用加法同态加密算法口-对词频信息进行加密处理。
三、一种基于全同态加密的检索方法
在加密信息检索研究中,结果的排序是衡量检索算法性能的重要指标之一。当前随着云计算技术的提倡和应用,加密文档必将呈爆炸式增加。排序的准确性成为对检索系统性能的客观要求,其主要目的是提高检索系统服务质量和检索效率。分析现有的加密信息检索算法发现,在保证查准和查全两方面性能的同时,对排序问题以及准确性方面考虑不够。
针对该问题,本文提出了一种面向云存储应用中的全同态加密的检索方法。全同态加密的检索方法是采用信息检索中的向量空间模型,计算检索出的文档与待查询信息之间的相关度,对检索词词频和倒排文档频率进行统计,然后采用全同态方法对文档进行加密并建立索引方法。检索后将加密文档与索引项密文一起上传到服务器端。
全同态加密检索及排序过程如图1所示。提交检索之前,同样先对检索语句进行分词、词干化,得到关键词明文序列并对明文进行加密。云端服务器对提交密文序列进行检索时,提交加密后的检索词。
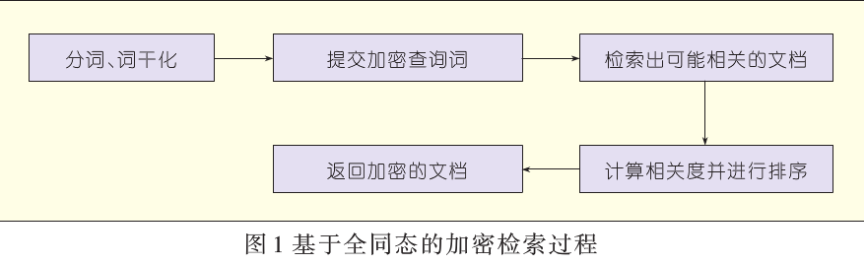
文档由每个关键词的权重向量表示,权重是词频与倒排文档频率对数的乘积的归一化。对用全同态加密后的词频、倒排文档频率进行操作可以得到权重。文档向量由公式(1)计算得到。
![]()
对于检索词采用同样方法来描述,取两者的内积即可得到两者的相关度,然后根据大小进行排序,将有效排序后的文档返回给用户。用户得到加密文档后,用私钥对文档解密得到原始文档。
通过全同态加密算法加密的明文数据可以在不恢复明文信息的情况被有效检索出来,即把最相关的文档返回给用户。既保护了用户的数据安全,又提高了检索的性能。
小知识之布尔(Boolean)模型
布尔(Boolean)模型是基于集合论和布尔代数的一种简单检索模型。它的特点是查找那些于某个查询词返回为“真”的文档。在该模型中,一个查询词就是一个布尔表达式,包括关键词以及逻辑运算符。通过布尔表达式,可以表达用户希望文档所具有的特征。由于集合的定义是非常直观的,Boolean模型提供了一个信息检索系统用户容易掌握的框架。查询串通常以语义精确的布尔表达式的方式输入。









