基于混沌的图像加密算法的硬件实现
数字图像数据量巨大,加密工作非常耗时,相比较于传统的软件实现,硬件电路因其并行高速的优点在实时处理中大受欢迎。那么我们今天就给大家介绍一下基于混沌的图像加密算法是如何通过硬件来实现的。
一、基于混沌的图像加密算法
1、 Baker映射
Baker映射作为一种基于位置置乱的离散二维混沌映射,是对高度不稳定的非线形混沌动力学系统Kolmogorov流离散化的结果,其定义如下:
(1)对于一个正方形的二维图像(N×N),首先将图像在水平方向上分为七个矩形块,每块有N×ni个像素,即每个矩形块长度为ni;
(2)每个矩形块再分成绝个子块,由于每个大矩形块有N×ni个像素,所以再分成ni个子块后,每个子块正好有N个像素。
(为了实现上的方便,一般只讨论N整除ni的情况,即分成的子块刚好都成矩形。)
离散Baker映射的公式如下:
![]()
式中:r,s一像素的列、行值,这里行是自下向上计数,列是自左向右计数;ni—分割图像时所产生的每一个小矩形块的长度;Ni前面i-1个小矩形块的各自长度之和;B(r,s)经过Baker映射以后的图像数组的列、行坐标。
现将一8×8的数字方阵进行Baker映射运算如下以透彻展示其置乱效果:
在图1(a)中,水平方向上分为3个矩形块,每个矩形块长度分别为2、4、2,即每块有16、32、16个像素,每个矩形块再分成2、4、2个小矩形块,此时每个小矩形块里面有8个像素。
_
Baker映射的这个特点,为我们提供了巨大的密钥空间。据统计,一副128×128的图像,其密钥空间可以达到2103数量级n1。
相比较于传统的基于位置置乱的图像块加密方法如猫映射等,其保密性大大加强。如此巨大的密钥空间,给图像攻击者带来了极大的破解难度。
任取一数做一说明:如元素37(图1(a)中s=3,r=4,Ni=2,ni=4),由式1得以B(r,s)(5,3),即37应当搬运到的新坐标为(5,3),从图1(b)中37的位置可以看出正是(5,3),注意这里行值s=3仍然是自下向上计数,列值r5是自左向右计数。
由于Baker映射分组的块数是任意的,也就是说,理论上可以分成N以内任意多块,只要满足子块的长度之和为N即可。
但应当指出的是如果仅凭位置置乱进行图像文件加密,图像直方图不会有任何变化,也就是说加密不能改变图像灰度的分布情况。那么难以抵抗差分攻击,取一副只有一个黑点的灰度图(其余均为白像素),经过Baker置乱以后,显然这个灰度值为0的黑点位置将被惟一确定,不断改变那惟一的黑像素的初始位置进行多轮加密,便可以知道大量的一一对应的位置关系,图像的安全性将大为降低。
基于上述考虑,在位置置乱的同时有必要改变图像的直方图,即把每个像素的灰度值逐个与若干个随机数进行位运算,以此来达到混淆图像的目的。
2、Logishc映射
Logistic映射是一种典型的混沌映射,其数学公式如下:
![]()
式中:μ∈[0,4]——分支参数,当μ=4时,此时的混沌系统具有遍历性,序列互相关为0,映射计算产生的混沌序列结果经过性能测试证明具有优秀的随机性,关于这一点已有很多文章对其进行论述。
二、硬件设计方案
现场可编程门阵列FPGA是在大规模集成电路基础上发展起来的一种可编程逻辑器件,包含大量的门电路,适合时序逻辑设计,具有很高的速度,而且器件具有用户可编程特性,因此近年来得到了广泛的工程应用。
1、加密算法的改进
在ic设计中,工程师往往特别关注电路实现的面积与速度。同时需要指出的是FPGA作为一种数字门阵列,在处理加法与移位运算上十分方便,而直接用其计算乘除却很占用资源,针对Baker映射中大量的乘除运算,可以运用VHDL全部将其转化为移位和相加运算,实验结果显示实现速度得到明显提高。
从公式(2)可知运算得到的将是浮点小数,采用硬件实现较为复杂,现对其进行改进以适应硬件电路的特点。
当x∈(o,1)时,运算得到的将是在0到l之间的随机小数,考虑到在实际的图像加密中需要的密钥流是0到255的随机整数,现将O到l之间的随机小数扩大256倍后取整,即将公式(2)变形如下:
![]()
为了硬件实现的方便,这里将本该连续分布的小数密钥流经过数字化的过程转变为O到255之间离散分布的整数密钥流,于是密钥周期由原来的无穷大降为了2的8次方,混沌系统出现退化,于是不可避免地造成了保密性的降低。作者按照美国商业部下属的国家标准与技术研究所制订的FIPS PUB 140-2标准对其进行了质量评估,其中的游程测试结果如表1所示。
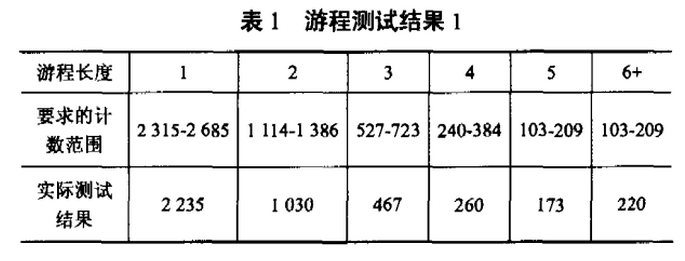
从表中可以看出退化后的混沌系统显然不再符合密钥序列质量标准。为了解决这一问题,作者这里再提出一种仍然是针对硬件实现的改进方案,即采用定点数表示小数的方法来完成,具体方法如下:
首先将初值(纯小数)按照“乘2取整”的方法转化为二进制数据,经过计算机模拟试验表明只要小数位数达到32位,那么产生的序列仍未脱离混沌状态。因此我们将初值转化为一个32位宽的逻辑矢量然后再参与Logistic迭代,每次迭代的结果仍然是一个小数,再取高8位输出就相当于左移了8位(即乘以256),得到的就是一个0到255之间的整数了,也就是我们所需要的伪随机序列。同样对其进行质量评估,结果如表2、表3所示。

从表中可以看出,经过改进的加密算法符合了FIPS PUB140-2标准。以上两种方案各有长处,前者计算量不大,速度较快,但保密性打了折扣,后者计算速度较慢,硬件实现面积较大,但可以保证安全性,实际中作者采用了后者。实验结果显示可以让明文图像的直方图得到相当程度的均衡,达到“替换”的目的,如图5(c)所示。
本文中选取的初始值是禹0.732*256四舍五入后为187,μ=4。经过16384次迭代运算产生伪随机序列,即图像加密中要使用的密钥流。
在已经生成了符合标准得密钥流基础上,为了有效地抵抗选择明文攻击,现在加密之前产生一个辅助密钥,这里提出一种方法:可从明文图像中任取8个像素点,每两个像素点一对,按比特位进行异或操作,得到4个8位的数ka、kb、kc、kd,然后将其相互做位运算,直至产生最后得辅助密钥。辅助密钥的选取可以选择其它方法,只要保证针对不同的加密图像结果不同即可。我们将这个辅助密钥与Logistic的初始值进行异或后再参与后面的迭代,从而使每个明文的各自独有的信息均参与到后面的迭代过程中去,使得每副密文图像均含有其本来图像的信息,这样一来,选择明文攻击将失效。
2、总体流程
用FPGA进行图像加密时首先应该将图像转化为硬件可以接受的数据流,这里我们采用了Matjab作为ISE(一种开发FPGA的软件平台)与图像的接口,然后通过书写ISE的Testbcnch激励测试文件将经过Matlab转化的图像数据送入FPGA。
基于FPGA实现的图像加密系统工作流程如图2所示。

另外,考虑到图像数据的巨大,本文采用的测试图共有16384个像素值,如果说直接使用片子内部的Distributcdram(分布式内存)存储将显得力不从心,假定一个像素用一个8位逻辑矢量表示,那么一副图像将耗用一个大小为16384×8的二维内存空间,这样大的空间,如果直接使用FPGA内部的LUT(查找表)的话,电路综合与实现将十分困难。这里我们采用FPGA内部的Blockram来进行图像数据的存储。Blockram是FPGA中分布在芯片左右两侧,独立于片内LUT和触发器之外的具有固定大小的块状RAM。实验操作时我们使用了ISE里面CORE GENFRATOR生成一个单口RAM(位宽为8,深度16 384)进行读写,如图3所示。

工作流程中各个单元均是在控制器发出相应的控制信号下进行工作的,如图4所示。

至于图像的解密,由于Bakcr映射牵扯到取模运算。除非另外能够得知中间的某些计算结果,否则一般条件下是不能直接完成逆运算的,故这里采用建立加解密位置对照表的方法来进行原始位置的恢复,具体方法如下:
利用IPCORE建立一个位宽14位(因为这里存放的数据不是灰度而是像素的地址2的14次方=16384),深度也是14位的存储区域(28KB)作为明文位置与密文位置的对照表。但是,应当指出对照表的建立也是占用FPGA的Blockram,所以只要Blockram空间够大,是完全可以实现图像的加解密的。我们采用的是Xilinx公司的xc3sl000型号的FPGA进行加密解密运算的,这种型号的FPGA其Blockram容量为54 KB,而实际图像大小为16KB,解密时建立的对应表大小28 KB。二者总和44 KB,尚在Blockram的容量范围以内,完全可以硬件实现。
三、实验结果与分析
图像加密前后的比较,如图5所示。

对于一个混沌系统而言,初始条件任意微小的改变都会引发系统在演化过程中得到完全不同的结果,表现出显著的随机性。如果解密的时候稍稍改动一下Logistic映射的初始值,把x0由0.732×256改为0.7325×256,而映射参数与Baker映射的分组方案均不做变化,对图5(b)进行解密如图6、图7所示。

显而易见,即便混沌映射初值仅有微小差异都不可能正确解密,这与上面的分析结果一致,保密性也因此可见一斑。
经测试,在xc3sl000型号的FGPA上完成解密运算仅耗用Slices186个,占芯片的2%,LUT耗用315个,占芯片总量的2%,最高运算频率达到了144.467 MHz,这样处理一帧128*128的数字图像耗用时间最短可以达到0.113 ms,我们曾经对上文描述的加密算法在VC+4- 6.0环境下仿真,由于软件实现中,指令必然是一条一条顺序进行的,这显然限制了加密速度的提高,在VC下运用timcGetTime函数,测试出完成这个加密运算C++-实现需要47 ms,比起硬件实现慢了许多,用FPGA实现图像文件加密的速度优势凸显而出。
实际应用中,为增大保密性,图像加密常常进行多轮迭代。通过迭代,可以使得初始明文图像的微小差异在加密过程中得到不断的扩散,从而有效地人为增加像素之间的相关性,进一步抵抗选择明文攻击。如果运用硬件迭代的话,那么其速度必然相比于软件成倍地增加,因此FPGA实现图像加密的速度优势将发挥得更加淋漓尽致。
小知识之Block RAM
Block RAM(BRAM):块随机存储器。Xlinx的SP3系列FPGA,包含两种RAM:Block RAM和分布式RAM(Distributed RAM)。
SP3含有最多1.87Mbit的Block RAM,主要应用于构造数据高速缓冲存储器、深的FIFO和缓冲器等。
每个Block RAM均为18Kbit,结构为真正双端口RAM,包含两套完备的36bit读写数据总线以及相应的控制总线。每块Block RAM均可被配置为单端口RAM(最大带宽为72bit)或双端口RAM(最大带宽为36bit),并支持级联,可级联多达104个同步18Kbit Block RAM。SP3的Block RAM支持多种纵横比、多种数据带宽转换,并支持奇偶性操作。










