基于MPI的伪随机序列并行加密算法
并行计算就是使用多计算机或多处理机的计算机来求解问题,它要比使用一台计算机的计算速度快很多,同时并行计算为求解巨大规模的问题提供了机会,因为这些大规模的问题所往往需要更多的计算步骤和更大的存储容量,正是多计算机或多处理机系统所拥有的。为了实现消息传递并行计算,现在存在几种方案或特定系统,其中比较流行的就是PVM(并行虚拟机)和MPI(消息传递接口)。 MPI是提倡的消息传递并行程序设计的标准之一,MPI2.O规范除支持消息传递外,还支持MPI的IIO规范和进程管理规范,加上其拥有移植性好,效率高,功能强等诸多优点,因此MPI正成为并行程序设计事实上的工业标准。
伪随机信号既有随机信号所具有优良的相关性,又有随机信号所不具备的规律性。这两个特点,使得它既易于从干扰信号中被识别和分离出来,又可以方便的产生和重复,因此伪随机序列在密码学、通信、雷达、导航等方面均有广泛的应用。目前由于网络的发展极为迅速,网络安全成为复杂而庞大的问题,虽然DES、RSA和数字签名等加密技术部分解决了当前的安全需求,但它们均存在并行度不足,没有充分利用网络的优势等缺点。因此,我们对基于M PI的伪随机序列并行加密算法进行探讨,研究如何利用MPI实现伪随机序列的并行产生或加密,为密码学的研究提供一种新的方向。
一、MPI简介
1、MPI的定义
对MPI的定义是多种多样,但不外乎下面3个方面,它们限定了MPI的内涵和外延:
(1)MPI是一个库,而不是一门语言。许多人认为MPI是一种并行语言,这是不准确的。但是按照并行语言的分类,可把FORTRAN+MPI或C+MPI看做是一种在原来串行语言基础之上扩展后得到的并行语言oMPI库可以被FORT RAN77/C/Fortran90/C++调用,从语法上说,它遵守所有对库函数或过程的调用规则,与一般的函数或过程没有区别。
(2)MPI是一种标准或规范的代表,而不是特指某一个对它的具体实现。迄今为止,所有的并行计算机制造商都提供对MPI的支持,可以在网上免费得到MPI在不同并行计算机上的实现,一个正确的MPI程序可以不加修改地在所有的并行机上运行。
(3)MPI是一种消息传递编程模型,并成为这种编程模型的代表和事实上的标准。MPI虽然很庞大,但是它的最终目的是服务于进程间的通信。
2、MPI的实现
MPI的实现包括MPICH、LAM、IBM MPL等多个版本,最常用和稳定的是MPICH。MPICH含三层结构,最上层是MPI的API,基本是点到点通信和在点到点通信基础上构造的集群通信(Collective Communication);中间层是ADI(Abstract Device InteIface)层,其中device可以简单地理解为某一种底层通信库,ADI是对各种不同的底层通信库的不同接口的统一标准;底层是具体的底层通信库oMPICH的1.0.12版本以下都采用第一代ADI接口的实现方法,利用底层d evice提供的通信原语和有关服务函数实现所有的ADI接口,可以直接实现,也可以依靠一定的模板间接实现。自1.0.13版本开始,MPICH采用第二代ADI接口。
3、MPI的通信模式
MPI共有四种通信模式:标准通信模式(standard mode),缓存通信模式(bufferedmode),同步通信模式(synchronous- mode)和就绪通信模式(ready- mode)。这几种通信模式对应于不同的通信需求,MPI为用户提供功能相近的不同通信方式,为用户编写高效的并行程序提供了可能。这几种通信模式主要是根据以下不同的情况来区分的:
①是否需要对发送的数据进行缓存?
②是否只有当接收调用执行后才可执行发送操作?
③什么时候发送调用可正确返回?
④发送调用正确返回是否意味着发送已完成?即发送缓冲区是否可被覆盖?
发送数据是否已到达接收缓冲区?针对这些不同的情况,MPI给出了不同的通信模式。
从表中可以看出,对于非标准的通信模式,只有发送操作,而没有相应的接收操作。MPI对不同的通信模式,在调用的命名上就区别开来,标准通信模式不加特殊的字母,而对其他三个通信模式提供三个附加的发送函数,用一个字母前缀表示通信模式:B用于缓存通信模式,S用于同步通信模式,R用于就绪通信模式。
在MPI采用标准通信模式时,是否对发送的数据进行缓存是由MPI自身决定,而不是由并行程序员来控制的;当用患对标准通信模式不满意,希望直接对通信缓冲区进行控制时可采用缓存通信模式;同步通信模式的开始不依赖于接收进程相应的接收操作是否已经启动,但是同步发送却必须等到相应的接收进程开始后才可以正确返回。因此,同步发送返回后,意味着发送缓冲区中的数据已经全部被系统缓冲区缓存,并且已经开始发送,这样当同步发送返回后,发送缓冲区可以被释放或重新使用;在就绪通信模式中,只有当接收进程的接收操作已经启动时,才可以在发送进程启动发送操作,否则,当发送操作启动而相应的接收还没有启动时,发送操作将出错。对于非阻塞发送操作的正确返回,并不意味着发送己完成,但对于阻塞发送的正确返回,则发送缓冲区可以重复使用。具体采用何种模式,就要根据实际的需要,因地制宜,才能取得最佳的优化和高效的结果。
二、伪随机序列并行加密算法
在香农证明了一次一密的密码体制是不可破的之后,这一结果大大的刺激了密码学的研究。若能以一种方式产生一伪随机序列,则利用这样的序列就可进行加密,这就是序列密码体制。序列密码的加密过程是先把报文、语音、图像和数据等原始明文转换成明文数据序列,然后将它同密钥序列进行逐位加密生成密文序列发送给接收者。接收者用相同的密钥序列对密文序列进行解密来恢复明文序列。序列密码不存在数据扩展和错误传播,实时性好,加密、解密容易,是一种广泛应用的密码系统,在密码学理论和应用中一直占重要地位。
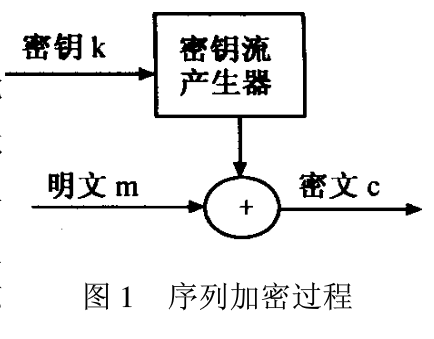
密钥流产生器实际上是一个算法,产生的密钥流通常是0~1数据流,因此称为流码。密钥流具有周期性,而且周期应尽可能的大,至少要和明文相等,并且具有随机性,是密码分析对它无法预测。为了使序列密码达到要求的安全保密性,密钥序列应具有伪随机性准则:
①序列周期充分长,通常不小于1016bit;
②良好的随机统计特性,即序列中每位接近均匀分布;
③序列线性不可预测性充分大。
目前比较常用的伪随机序列并行算法有两种:n级线性反馈移位寄存器( LFSR)伪随机序列的并行算法和组合前馈网络伪随机序列的并行算法。我们分别介绍如下。

1、n级线性反馈移位寄存器
(1)反馈移位寄存器
一般的反馈移位寄存器的基本结构如图2所示。
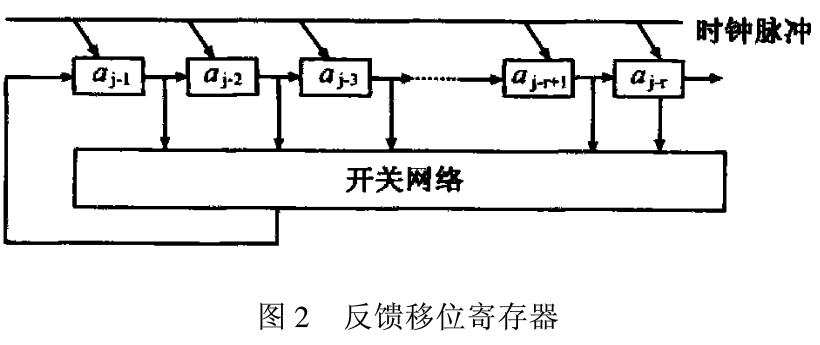
图2可以看成是一个r级反馈移位寄存器,它由串联的n个二元移位寄存器及一个开关网络构成,其中aj-1,aj-2,...,aj-r分别是第1级,第2级,..2,第r级寄存器。每个二元寄存器是一个双稳态触发器,它的两种状态分别记为“O”和“1’’,每个触发器看成一级。开关网络是具有r个输入端和一个输出端的组合门电路,它可由含有r个逻辑变元x1,X2,...,Xr的布尔函数:Xr+ 1=f(x1,X2,...,Xr)来表示,这个函数称为该组合门电路的反馈逻辑函数。反馈逻辑函数在反馈移位寄存器中起决定作用,它是由r个逻辑变元通过“与”、“或”、“非’’、“模2加”等逻辑运算连接起来的关系式。
(2)线性反馈移位寄存器(LFSR)
如果用n元布尔函数f(x1,X2,...,Xn)可以表示为n个变元x1,X2,...,Xn的线性齐次函数f(x1,X2,...,Xn)=c1xn+C2Xn-1+…+CnX1,其中C1=O或1,则以f(x1,X2,...,Xn)为反馈的移位寄存器称为线性反馈移位寄存器。图3是一个n级线性反馈移位寄存器,与反馈移位寄存器类似,它由串联的n个二元移位寄存器及一个开关网络构成其中ai+n-1,ai+n-2,...,ai分别是第1级第2极,...,第n级寄存器。
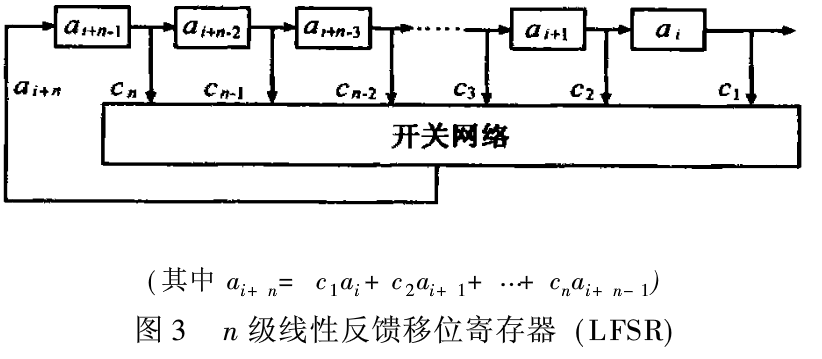
多项式f(x1,X2,...,Xn)=co+cixn-1,...,CnX(co=ci=1)称为LFSR的连接多项式。当一级线性移位寄存器产生的序列周期长度为2n—1时,这个序列成为m序列。
2、组合前馈网络
用前馈序列能产生具有良好统计特性的序列,它通过一个或多个m序列加上一个非线性前馈网络来产生具有周期长、随机统计特性好、线性复杂度较高的序列。一般的组合前馈序列产生器如图4。
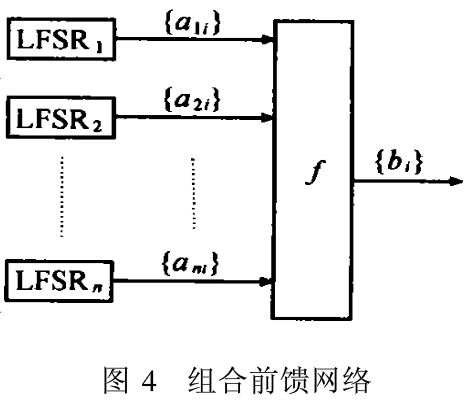
其中{a1i},{a2i},...,{ani}的级数分别为n1,n2,...,nn的m序列,f(X1,X2,....,Xn) 为n元非线性组合函数,序列{bi}为b=f(a1i,a2i,...,ani),称{bi}为由序列{ aii},{a2i}, …,{ani}及厂产生的组合前馈序列,f称为组合函数。
三、加密算法实现
现在我们就用MPI在SIMD-CREW模型上实现n级线性反馈移位寄存器(LFSR)做个说明。具体步骤:
(1)以管理员的身份登录每台主机,在所有主机上建立一个同样的账户(当然也可以每个机器使用不同的用户名和账户,然后建立—个配置文件,使用命令行的方式运行程序),然后,运行下载的安莓享件,将MPICH安装到每台主机上。
(2)安装好MPICHIJ之后,就对每台计算机进行注册和配置。其中注册必须每台计算机都要进行,配置只要在主控的计算机执行就行了。注册的目的是将先前在每台计算机上申请的账号与密码注册到M PICH中去,这样M PICH才能在网络环境中访问每台主机。
(3)运行MPICH提供的配置程序“M PICH Configuration toor”来配置主控机,使其能访问其他计算机,并让程序能在各台计算机上执行。
(4)将MPICH与编译环境整合起来。
(5)算法描述。其中n是2的幂,当前各存储器的值存储于数组A[]中,连接多项式的系数存储于数组C[],数组B[]是辅存。以各寄存器为结点构造平衡二叉树,从叶子结点向根结点遍历,计算反馈输出值。
输入:各寄存器的初值
输出:伪随机m序列
MPI_ Init(&ar gc,&argv);
MPL Comm - rank(MPI_ COMM_ WORLD,
&rank);//当前进程标识
M PI_ Comm_ size(MPI_ COM M_ WORLD,&size);
//通信域中的进程个数
MPL Get-processor_ name (processor_ name &namelen);
for(i_1;i<=n;i++)
{ if( rank==i)
B[O,i]=A[i]&C[i];
}
for(h= 1; h<= log(n)/log(2);h++)
//求级联多项式的值
for(i= 1;i<=n/pow(2,h);i++)
{if( rank==i)
B[ h,i]=B[h,2i- 1]^B[ h-1,2i];
}
for(i_1;i<=n;i++)
{if(rank==i)
A[i-1]=A[i];//移位寄存器移一位
}
A[n]=B[log(n)/log(2),1];
A[o]=B[log(n)/log(2),1];
MPI_ Finalize();
(6)加密算法复杂度分析。该算法在实现n级LFSR时使用孔个处理器在O(lg(n))时产生序列的—位。如果加密序列的长度为w,那么该算法复杂度为O(Wl(n)),而串行算法需要O(wn)的时间,理论上如果处理器越多,伪随机序列并行算法将越有效。
小知识之MPI
MPI是多点接口(Multi Point Interface)的简称,是西门子公司开发的用于PLC之间通讯的保密的协议。MPI通讯是当通信速率要求不高、通信数据量不大时,可以采用的一种简单经济的通讯方式。







