如何用GPU实现的AES加密
图形处理器( Graphics Processing Unit,GPU),亦称图形处理单元。是一种专用图像渲染设备,分担了中央处理器( CPU)的二维或三维图形处理任务。随着近年来各种硬件加速的出现使显卡性能突飞猛进。正是这个时候,第一款可编程图形流水线(pro-grammable graphics pipeline)的GPU产品诞生,即Ge-Force3。从此,可编程的着色功能加入了硬件。
GPU拥有了更大的可扩展性和适应性。GPU高度并行化的架构和可编程的着色器使人们渐渐开始用它计算通用任务,实现了对通用数据的处理。GPGPU技术也是在这个时期开始发展起来的。GPGPU代表General Purpose Computing on Graphics Processing U-nit,就是“图形处理器通用计算技术”。这种新兴的加速技术试图把个人计算机上的显卡当作CPU这样的通用处理器来用,使显卡的强劲动力不仅发挥在图形处理上。用着色语言实现的GPGPU技术是第一代的GPGPU技术,也称为经典GPGPU、传统GPGPU。但是传统的GPU几乎专门用来进行浮点操作,因为整数操作只能使用浮点数尾数来完成,所以就不能完成那些要求按位逻辑操作的处理。然而随着GeForce 8系列GPU的出现,多种新的扩展和功能被引入。新的整数处理功能不仅包括算术操作,还包括按位的逻辑操作,以及移位操作。然后,数组变量代替纹理提供了一种灵活的方式存储常量表。目前,如何方便、快速地实现加密算法是密码学领域遇到的一个新的挑战。而GPU其特有的并行计算特性如果应用到AES加密算法,将显著提高该算法的加密速度。文中正是基于上述原因,提出了一种基于传统OpenGL可编程模型的一种AES加密算法。
文中首先将介绍传统GPU编程模型及相关概念,然后概述AES加密算法,接着介绍AES加密算法在GPU上的实现,最后将与在传统CPU上实现的AES加密算法进行性能上的比较。
一、图形化处理单元
1、图形流水线
图形流水线是GPU工作的通用模型。它以某种形式表示的三维场景为输入,输出二维的光栅图像到显示器,也就是位图。GPU中的图形流水线的总体框架如图1所示。上半部分为OpenGL传统图形流水线,下半部分为OpenGL可编程图形流水线。
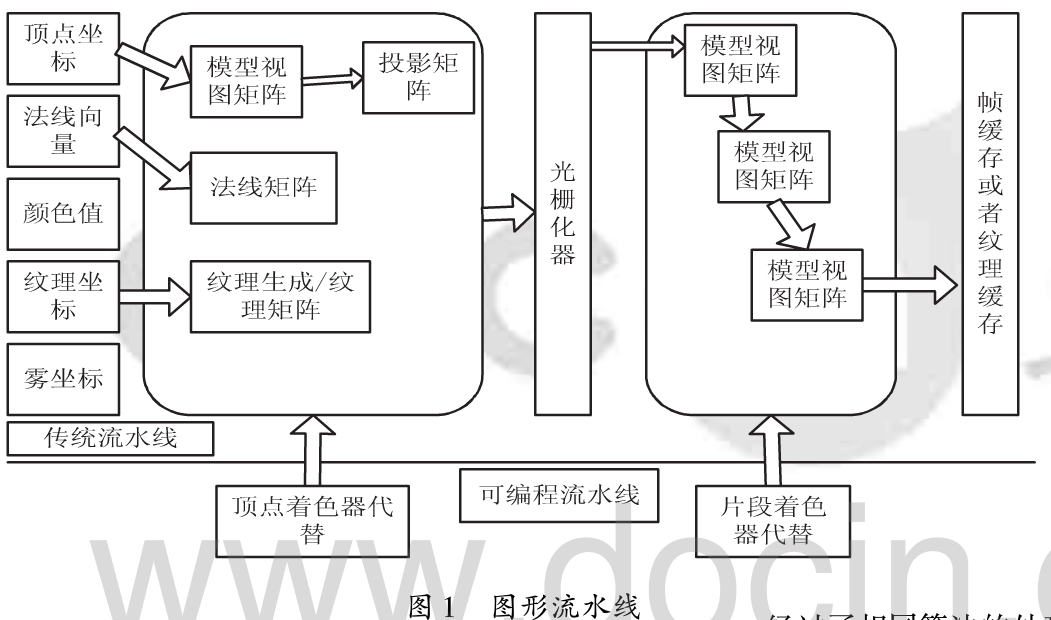
传统图形流水线,首先经过顶点级的光照计算和坐标变换求出每个顶点的光照颜色值,同时还将顶点坐标从物体坐标系转换到裁剪空间。然后,对每个三角形进行光栅化处理并对三角形顶点的颜色进行双线性插值得到了三角形中每一个像素的颜色值。接着进行纹理映射,即根据每一个像素的纹理坐值将纹理图颜色分配到每个像素上。最后进行颜色混合计算和雾化效果计算得到的结果将会放进帧缓存并显示到屏幕上。
可编程着色管线意味着可以用小型程序控制顶点和片段的处理,即顶点着色器和片段着色器。这种小型程序是由OpenGL着色语言(GLSL)编写。着色器( shader),又叫着色单元,实际上就是GPU的处理器。一般情况下,一个GPU会有多个处理器(几百上千个),它们同时工作,体现了GPU大规模并行处理的能力。进行几何计算的处理器叫顶点着色器,它负责对顶点进行坐标变化、投影变换等;进行片段的颜色处理的叫做片段着色器D应用程序输入GPU的是三维的点云数据。从流水线输入端直到顶点着色器,流水线计算的对象都是三维几何模型;从光栅化开始,所有的操作都是针对二维的像素了。
2、经典GPGPU技术
在了解GPGPU技术之前,有必要了解一下GPU的并行计算模型SIMD,与数据并行模型实际上是完全相同的。GPU的并行概念实际就是数据并行(dataparallelism)。它是指多个不同的数据同时被相同的指令、指令集或者算法处理。回顾图形流水线,每个顶点都经过了相同的流水线,实际上流水线只是个抽象的概念,它指的就是一段算法。因此,GPU计算任务的本质与程序中的循环语句是相同的,但是需要串行处理的数据量减少到了Nparallel,如公式(1)所示。
![]()
式中,Ndata是数据的总个数,Ntlu-eads是线程的个数。当每个线程处理一个数据所需的时间相等时,数据并行处理的速度是单线程循环语句的速度的Nthreads倍。
经典GPGPU借助的是GPU图形流水线的大规模并行计算能力。成千上万的顶点都流经同样的流水线,成为屏幕上的像素。由于每个顶点和每个像素都经过了相同算法的处理,因此SIMD模型就是GPU计算的基本模型。
目前为止,还有一些很重要的问题亟待解决。比如,流水线的终点是帧缓存或者显示器,而科学计算一般需要写入存储器,这是如何做到?图形流水线处理的是坐标信息和像素信息,如何才能处理通用数据?在OpenGL提供有限数量的图形处理函数的情况下,如何制定科学计算所需要的算法?对于第一个问题其实就是纹理缓存口第二个问题,其实用户只要选择合适的数据类型来声明数组,再将数组作为数据的容器,最后把这样的数组看作一幅纹理并传输至纹理缓存就可以啦。第三个问题其实就是通过着色语言和着色器来实现的。
二、AES算法概述
AES加密算法是由Daemen和Rijmen早期所设计的Square改良而来。使用的是置换一组合架构,在软件及硬件上都能快速地加解密,相对来说较易于实际操作,且只需要很少的内存。作为一个新的加密标准,目前正被部署应用到更广大的范围。
该算法具有如下几个特点:
(1)对称密钥密码;
(2)块密码;
(3)支持128位块大小,当前该算法的联邦信息处理标准规范只支持固定大小的128位块;
(4)支持128位、192位、256位密钥长度。不同的密钥长度加密的轮数不一样,文中使用128位的密钥长度。
AES加密过程是在一个4x4的字节矩阵上运作,这个矩阵又称为“体( state)”,其初值就是一个明文区块(矩阵中一个元素大小就是明文区块中的一个Byte)。
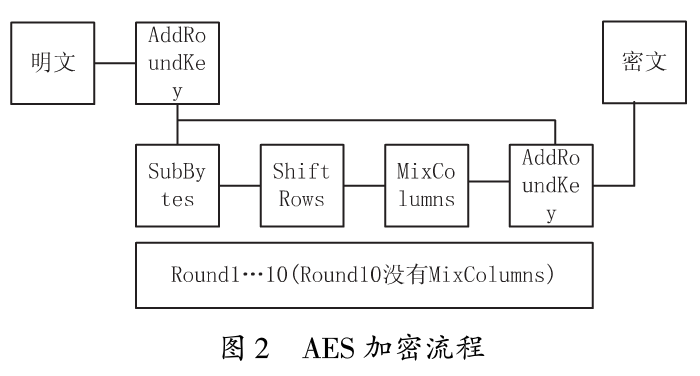
加密时,各轮AES加密循环(除最后一轮外)均包含如下4个步骤(加密过程中使用的密钥是由Rijndael密钥生成方案产生):
(1) AddRoundKey:矩阵中的每个字节都与该次回合金钥做XOR(异或)运算。
(2) SubBytes:矩阵中的各字节透过一个8位元的S-box进行转换。,这个步骤提供了加密法非线性的变换能力。S-box是一个具有256个元素的已知数组。
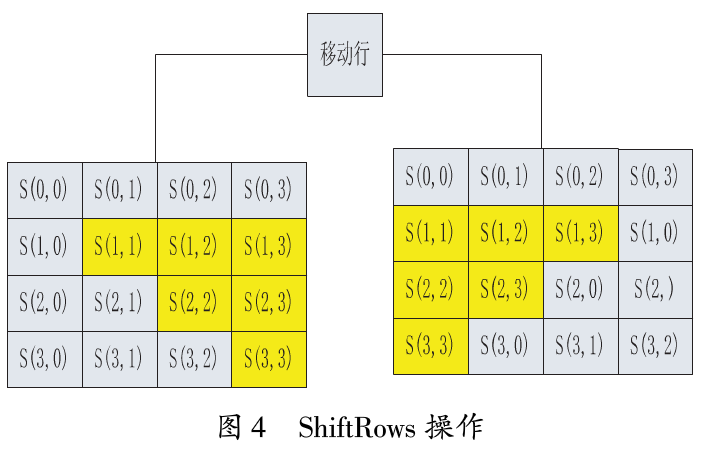
(3) ShiftRows:针对矩阵的每一个横列操作的步骤。在此步骤中,每一行都向左循环位移某个偏移量。在AES中(区块大小128位元),第一行维持不变,第二行里的每个字节都向左循环移动一格。同理,第三行及第四行向左循环位移的偏移量就分别是2和3。
经过ShiftRows之后,矩阵中每一竖列,都是由输入矩阵中的每个不同列中的元素组成。
(4) MixColumns:每一直行的四个字节透过线性变换互相结合。每一直行的四个元素分别当作1,x2,x3,x4的系数,合并即为GF(28)中的一个多项式,接着将此多项式和一个固定的多项式C(x)=3x3 +X2 +X +2在moddulo4+1下相乘。此步骤亦可视为Rijndael有限域之下的矩阵乘法。MixColumns函数接受4个字节的输入,输出4个字节,每一个输入的字节都会对输出的4个字节造成影响。因此ShiftRows ows和MixCoIumns两步骤为这个密码系统提供了扩散性。其流程图如图2所示。
三、AES在GPU上的实现
了解了可编程GPU流水线及AES算背景后,就可以开始着手设计该算法。如图2,是AES加密算法的流程口图中大方框内的内容就是GPU代替CPU实现的步骤。首先考虑输入问题。明文是应用程序的输入,这可以通过二维纹理的形式存入GPU的纹理缓存,以供GPU使用。其实每一个Round就是一次渲染,每次渲染是由四个Pass组成,这四个Pass分别是SubBytes,ShiftRows,MixColumns,AddRoundKey。优化后将SubBytes和ShiftRows合并为一个Pass。
1、初始化阶段
在初始化阶段,需要用CPU来扩展密钥,生成十组新的密钥,用于每一次Round中的AddRoundKey。然后需要将输入数据(明文)InPutData[Width][ Height],绑定到一张二维纹理。输人数据的大小
是Width木Height水4个字节。由于明文存储在二维纹理中,所以需要快速准确地用纹理坐标中找到对应的数据。通过如下的Draw函数能实现该功能,纹理坐标(顶点坐标+1.0)/2。由于需要将每个Pass的结果输出到纹理缓存,所以需要分别创建四张二维纹理及四个帧缓冲区,并一一绑定。
void draw(int w,int h){
float w_bias = 0.5/w;float h_bias =0.5/h ;
float h_inverse = 1.O/h;float w- rnverse = 1.O/w;
gIBegin( GL_POINTS)
for(int i = O;i < w;i++) {
for(int j = O;j < h;j++) {
gIVertex3f( i * 2 * w_inverse+2 * w_bias-l, j * 2*h_bias-l', 0. 0) ; }
gIEnd()
}
2、SubBytes操作
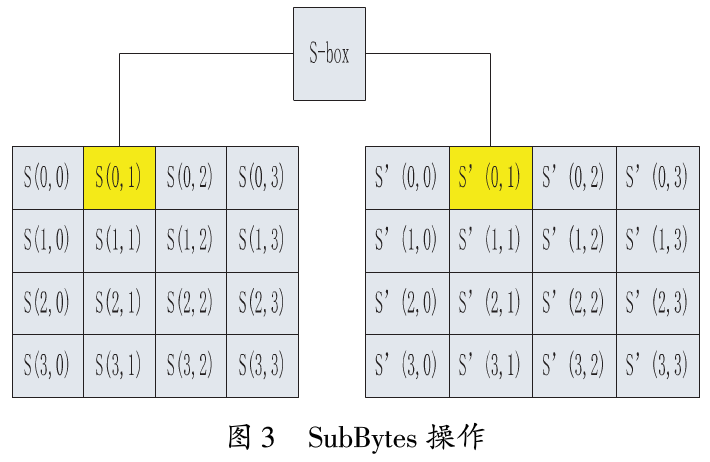
SubBytes操作使用一个非线性的称为S-box的替换表,独立地代替字节,如图3所示。S-box是提前已计算好的一个统一的表,所以可以直接预先存储在GPU内存中,在对应的Shader( SubBytes)中声明。
3、ShiftRows操作
ShiftRows操作循环地移动体的最后三行,从而有效地让行数据变得不规则,如图4所示。其实此时可以做一个简单的优化,就是把SubBytes操作和ShiftRows操作融合到一个Pass。
4、MixColumns操作
MixColumns操作的目的是使每一列的数据变得不规则,如图5所示。

该操作通过对每一个列向量执行矩阵乘操作来完成,如公式(2)所示。因为乘法是在AES的一个有限域上操作,所以不能使用一般的乘操作。

这个有限域的闭包在一个字节的范围内。其程序清单如下:
void MixColumns( vec2 pos)//pos为纹理坐标
{//InputDataMix为sampler2D的und'orm变量
data =ivec4( texture2D( InputDataMix, pos));
int a[4];int b[4];int h;
for(int c=O;c<4;c++){ a[c]=data[c]; if( data[c]>127){ h=OxOOOOOOFF;}
else{ h=Ox00000000;}
b[c].(data[c]<<1) &OxOOOOOOFF;
b[c]=(OxOOOOOOIB&h);
}
data[O]=b[O]^a[3]^a[2]^b[1]^a[1];
1*2*a0+a3+a2+3*al*/
data[1]=b[1]^a[O]^a[3]^b[2]^a[2];
1*2*al +a0+a3 +3*a2 */
data[2]=b[2]^a[1]^a[0]^b[3]^a[3];
1*2*a2+al+a0+3*a3 */
data[3]=b[3]^a[2]^a[1]^b[O]^a[0];
1*2*a3+a2+al+3*a0*/
OutputData=vec4( data);
//OutputData是varying变量}
5、AddRoundKey操作
这个操作是很简单的。就是用当前轮的密钥与对应的每个字节进行异或操作。
四、性能对比
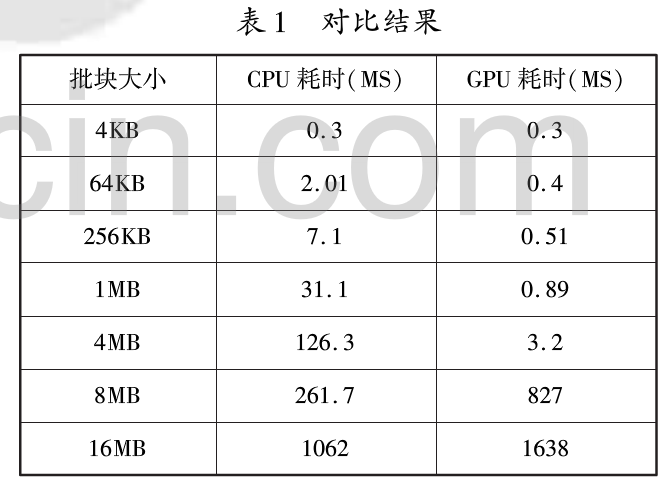
有了一个在基于GPU的AES实现,现在就可以测量一下该方法的性能。这里忽略了解密,因为在AES算法中,加密和解密的性能是相同的。性能对比如表1所示。批块大小是指,每次被送往GPU中的数据量。
测试的机器配置如下:
(1) CPU:Intel( R) XeOn( R) W3520 2.67GHZ
(2)内存:4GB
(3)显卡:GTX 470显存:IGB
(4)系统:Windows7 x64旗舰版
从表1可知,当批块小于4MB时,基于GPU的AES加密方法显著地提高了加密速度。当批块大小为4MB时,加密速度大约是基于CPU加密的40倍。当批块过大时,由于纹理大小的限制加密速度显著降低。此时可以把明文分割为4MB的批块,同时使用多张二维纹理进行加密。
小知识之GPU
GPU英文全称Graphic Processing Unit,中文翻译为“图形处理器”。(图像处理单元)GPU是相对于CPU的一个概念,由于在现代的计算机中(特别是家用系统,游戏的发烧友)图形的处理变得越来越重要,需要一个专门的图形的核心处理器。







